




Echte KI im Input Management in Versicherungen
In der Beitragsreihe zum „Intelligenten Input Management“ veröffentlichen wir den Gastartikel von Dr. Patrick Bartels, Spezialist für KI im Input Management und CEO von inserve.
Zwei parallele Entwicklungen machen KI im Input Management gerade besonders spannend. Zum Einen steigen die Verfügbarkeit von (digitalen) Trainingsdaten und skalierbarer Rechenleistung in der Cloud. Zum Anderen nimmt die Notwendigkeit zur Digitalisierung stetig zu. Beides zusammen führt dazu, dass das Veränderungspotenzial heute tatsächlich größer ist als je zuvor. Grund genug, den aktuellen Stand kritisch zu betrachten.
Künstliche Intelligenz (KI) als Sammelbegriff
Spätestens seit ChatGPT breite öffentliche Aufmerksamkeit erfährt, wird Künstliche Intelligenz in allen Unternehmen und auf allen Ebenen diskutiert. Aber schon lange vorher verbanden sich mit dem Begriff der KI zahlreiche Sehnsüchte und Verheißungen, ohne die der aktuelle Hype kaum möglich wäre.
Nicht zuletzt aufgrund dieser stetig wachsenden Popularität haben alle Hersteller und Anbieter von Lösungen im Input Management Versionen mit dem Vermerk “jetzt auch mit KI” im Angebot. Dabei ist KI keine Funktion und auch keine Software, die man herunterladen kann. Erst recht kein Produkt, dass man von der Stange bestellt (“Guten Tag, ich hätte gerne 100g KI, dünn geschnitten bitte“).
Grundsätzlich ist KI nichts Mystisches. KI ist auch keine Technologie, sondern eine Mischung aus verschiedenen Technologien und Forschungsrichtungen. Erst recht wird es kompliziert, wenn man die verschiedenen Anwendungsbereiche betrachtet. Deswegen hat jeder Hersteller oder Anbieter eine andere Definition von KI („idealerweise“ immer eine, die die eigene Argumentation und Produktvermarktung unterstützt).
Aus den vielen Forschungsrichtungen der KI ist vor allem das maschinelle Lernen (Machine Learning) im Input Management der Versicherungen interessant - sprich KI in der Versicherung.
Maschinelles Lernen im Input Management
Achtung, Theorie: Maschinelles Lernen ist ein Oberbegriff für die Erzeugung von Wissen aus Erfahrung. Ein System lernt aus Beispielen und kann diese nach Abschluss der Lernphase auf neue Daten anwenden. Dazu bauen Algorithmen beim maschinellen Lernen ein statistisches Modell auf, das auf Trainingsdaten beruht und welches gegen Testdaten geprüft wird. Die verwendeten Algorithmen und Methoden sind der Kern eines solchen KI-Modells. Es werden nicht einfach Beispiele auswendig gelernt oder reproduziert (wie beim Programmieren von Regeln), sondern Muster und Gesetzmäßigkeiten in den Lerndaten erkannt.
Das Grundprinzip ist also immer das gleiche: Eingabedaten werden bereitgestellt, um Ausgabedaten möglichst präzise zu bestimmen. Je nachdem, was die Aufgabenstellung ist, kommen andere Algorithmen und Methoden zum Einsatz. Daher lassen sich Machine-Learning-Modelle nicht nur für reine Textdaten, sondern auch für Bilddaten verwenden.
Konkret für das Input Management bedeutet das, dass die Modelle je nach Anwendungsfall anhand von echten Mustern als Trainingsdaten trainiert werden. Dabei ist es “der KI” grundsätzlich egal, ob es sich bei den Trainingsdaten um ganze Stapel, einzelne Dokumente, Textelemente oder optische Merkmale auf einer Seite handelt. Für jede Erkennungsaufgabe gibt es geeignete Algorithmen und Methoden, um die Aufgabenstellung optimal zu erledigen.

Quelle: inserve
Ein gutes, weit verbreitetes Anwendungsbeispiel, ist die Klassifizierung eingehender Dokumente in Versicherungen. Sachbearbeiter trainieren das System, indem sie die Klassifikation genau so vornehmen, wie bisher auch. Diese Dokumente sind die Trainingsmuster mit denen das System lernt, beispielsweise Versicherungsanträge, Kündigungen oder Meldebögen zu unterscheiden. Nach der Trainingsphase kennt das System die Merkmale, Unterschiede und Gemeinsamkeiten und erkennt im laufenden Betrieb eingehende Dokumente selbständig.
Anschließend können im Input Management Prozess andere KI-Modelle auf die gleiche Art trainiert werden, beispielsweise Ankreuzfelder (Checkboxes) zu erkennen und angekreuzte von nicht angekreuzten Feldern zu unterscheiden. Nur allein anhand von Mustern. Das sind dann natürlich andere KI-Modelle als die zur Klassifikation von Textdokumenten.
Genau wie bei Menschen funktionieren KI-Modelle in ihrer fachlichen Domäne besonders gut, je spezialisierter sie trainiert und eingesetzt werden. Auch bei Menschen ist davon auszugehen, dass ein ausgebildeter Buchhalter im Rechnungswesen bessere Ergebnisse liefert als ein Generalist, der in allen Bereichen eines Unternehmens mal ein bisschen angelernt wurde. Ein Schlüssel zum erfolgreichen Einsatz von KI im Input Management ist, zu jeder Aufgabenstellung das optimale Maß an Spezialisierung und Generalisierung für die KI zu finden und diese Modelle miteinander zu kombinieren.
Intelligent Document Processing mit KI
Früher haben in allen Poststellen ausschließlich Menschen gearbeitet - es kam 100% natürliche Intelligenz zum Einsatz. Insofern ist der Begriff “Intelligente Dokumentenverarbeitung” beziehungsweise “Intelligent Document Processing” (IDP) streng genommen so alt wie die Poststelle selbst.
Dennoch wird der Begriff gerade immer häufiger verwendet. Beim Intelligent Document Processing werden die Funktionen im Input Management, die bisher Menschen erledigt haben, durch spezialisierte KI-Modelle ersetzt. Im Idealfall werden alle Funktionsschritte durch KI-Modelle ersetzt, so dass eine weitgehend automatisierte Verarbeitung von eingehenden Dokumenten im Input Management möglich ist.

Quelle: inserve
Die verschiedenen Lösungsoptionen am Markt unterscheiden sich oft anhand der Vollständigkeit, welche Funktionen tatsächlich durch KI-Modelle ersetzt werden und an welchen Stellen doch noch klassisch Regeln programmiert werden.
Ein weiteres Unterscheidungsmerkmal ist die Erkennungsleistung der einzelnen Modelle und dieser in Kombination. Denn die Gesamtleistung des Input Management ist nur so gut wie die Kombination aller einzelnen KI-Modelle.
Anwendungsbeispiel: Fachdatenextraktion aus Fahrzeugscheinen
Fahrzeugscheine sind schwer zu automatisieren
Lassen Sie mich die Leistungsfähigkeit der konsequenten Nutzung von KI im Intelligent Document Processing anhand eines Anwendungsfalls darstellen. Bei Fahrzeugscheinen kommen herkömmliche OCR-Systeme und „normale“, regelbasierte Systeme an ihre Grenzen:
- der Text ist dünn gedruckt und sehr blass

Quelle: nmann77 – stock.adobe.com
- der Text steht dicht an den Linien
- im Hintergrund ist ein farbiges Muster mit einem Farbverlauf
- die Dokumente werden vom Absender oft schief fotografiert
- Fotos der Dokumente haben oft eine schlechte Qualität
Alle diese Faktoren führen dazu, dass die OCR den Text schwer erkennen und die Erfassungssoftware die Daten schlecht extrahieren kann.
Konsequente Nutzung von KI im Input Management als Lösung
Für die Verarbeitung komplexer Dokumente wie beispielsweise Fahrzeugscheine können beim Intelligent Document Processing verschiedene spezialisierte KI-Modelle kombiniert werden, um eine weitgehend automatisierte Verarbeitung zu erreichen.
Bildoptimierung: Anhand von guten und schlechten Beispielen erlernt das KI-Modell die relevanten von den irrelevanten Bildpunkten zu unterscheiden. Das Modell “weiß” daher, welche Bildpunkte Nutzdaten sind, also Text, und welche Störungen sind, beispielsweise Hintergründe, Linien oder andere Bildartefakte. Als Ergebnis gibt das KI-Modell nur den echten, relevanten Text zurück. Dieser kann optimal durch eine OCR erkannt werden.
OCR: Auch bei der Zeichenerkennung kommen inzwischen KI-Modelle zum Einsatz, deren Algorithmen ständig weiterentwickelt werden. Solche OCR-Anwendungen können in ihrer Erkennung speziell auf konkrete Anwendungsfälle, wie die Fahrzeugscheine, trainiert und optimiert werden. Vor allem im Vergleich zu stand-alone Standardlösungen sind so erheblich bessere Erkennungen möglich.
Klassifikation: Anhand von wenigen Beispieldokumenten erlernt ein KI-Modell, Fahrzeugscheine von anderen Dokumenten zu unterscheiden. Basis für eine gute Erkennungsleistung ist eine hervorragende OCR auf Basis von optimierten Bilddaten, siehe oben. Ein spezielles KI-Modell zum sicheren Erkennen von Fahrzeugscheinen ermöglicht damit eine intelligente Weiche, um die Fahrzeugscheine automatisiert auf einer Art Überholspur zu verarbeiten.
Extraktion: Auch die Extraktion kann schnell anhand weniger Beispielfelder trainiert werden. Dazu klickt ein Sachbearbeiter die benötigten Datenfelder auf dem optimierten Fahrzeugschein an. Das System erlernt im Hintergrund alle relevanten Merkmale, die das gesuchte Feld klassifizieren.
Validierung: Nicht nur die Erkennungsraten sind für einen guten automatisierten Prozess relevant, sondern auch die sichere Erkennung von (möglichen) Fehlern. Dazu können ebenfalls KI-Modelle trainiert werden. Genau wie die meisten Menschen mehr oder weniger intuitiv erfassen können, ob ein Datenfeld vermutlich ein Datum ist oder nicht, erlernt das System anhand von verifizierten, korrekt erkannten Werten und nicht korrekt erkannten Beispielen, diese aufzufinden.

Quelle: inserve
Human-in-the-Loop als Schlüssel
Bei aller Faszination für KI und lernende Systeme bleibt der Mensch mit seiner Erfahrung (derzeit noch) das Maß der Dinge. Alle KI-Modelle, die ich oben beschrieben habe, liefern neben den erkannten Werten eine Konfidenz. Das ist die errechnete Sicherheit, mit der Entscheidung vom System getroffen wurde. Anhand dieser Kennzahl kontrollieren menschliche Mitarbeiter die Entscheidung der KI und korrigieren oder verifizieren diese. Dadurch wird in kontinuierlicher Verbesserungsprozess der Erkennung aller KI-Modelle erreicht.
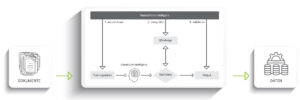
Quelle: inserve
Mein Fazit zu KI im Input Management
Durch die zunehmende Verfügbarkeit von Rechenleistung und fortschrittlichen Algorithmen in Kombination mit digitalen Trainingsdokumenten erreichen gut trainierte KI-Modelle inzwischen deutlich höhere Erkennungsleistungen als herkömmliche Lösungen. Und noch dazu deutlich besser skalierbar!
Die hohe Erkennungsleistung einzelner KI-Modelle kann zu fachspezifischen Erkennungsprozessen im Input Management kombiniert werden. Der resultierende, intelligente Gesamtprozess stellt alles in den Schatten, was an Standardlösungen in den meisten Häusern vorherrscht.
Durch Intelligent Document Processing
- sinken die Prozesskosten im Input Management.
- werden Dokumente aller Art in Sekunden statt Stunden bearbeitet.
- stehen Daten aus eingehenden Dokumenten vollständig im Kernsystem zur Verfügung.
- werden Fachmitarbeitende von Routinearbeiten entlastet und die Dunkelverarbeitung gesteigert.
- wird die Kundenzufriedenheit gesteigert.
Ich bin der festen Überzeugung, dass KI-basierten Systemen die Zukunft gehört. In naher Zukunft werden herkömmliche, regelbasierte Input Management Systeme genauso altmodisch sein, wie eine manuelle Poststelle heute.
Über den Autor

Als promovierten Wirtschaftsinformatiker zeichnet Dr. Patrick Bartels eine seit 20 Jahren anhaltende Affinität zu Künstlicher Intelligenz sowie der Anwendung von KI-Systemen aus.
Neben seiner aktuellen Verantwortung als CEO von inserve beeinflusste sie auch seine Leistungen als IT-Projektleiter im Bereich Dokumentenprozesse im Input und Output Management und KI in Versicherungen. Mehr als 15 Jahre lang gestaltete er so zukunftsfähige Lösungen, unter anderem als Leitender Angestellter bei der VHV Versicherung.

