Abstract: Im ersten Teil der Artikelserie sind wir auf die notwendigen Schritte zur Erweiterung einer bestehenden Input Management Lösung durch KI-Services eingegangen und haben beleuchtet, mit welchen möglichen Lösungsansätzen der Pentadoc die Anforderungserhebung beschleunigt werden kann. In diesem Teil der Artikelserie werden wiruns genauer mit der Konzeptionsphase befassen und Tipps geben, wie moderne Architekturen im Input Management entwickelt werden können.
Phase 2 – Die Konzeption: In klaren Stufen zum Go-live
In der Konzeptionsphase ist die Ziellösungsabwägung ein entscheidender Punkt. Die geplante SOLL-Lösung bzw. -Architektur ist richtungsentscheidend, wie die passende Transformations- bzw. Migrationsstrategie aussehen wird.
Folgende Fragen müssen im Rahmen der Konzeption beantwortet werden:
Kann der präferierte KI-Service in die bestehende Input Management Lösung eingebunden werden?
Wenn ja, welche Ziel-Architektur realisiert daraus?
Wenn nein, ist eine Ablösung der bestehenden Input Management Lösung durch KI-Services geplant?
Erfahrungsgemäß empfehlen wir als Pentadoc in dieser Phase die Erstellung einer IT-Gap-Analyse, in der die bereits bestehenden Systeme auf ihre Funktionen hin untersucht werden und eine sinnvolle funktionale und technische Abgrenzung des zukünftigen Input Managements vorgenommen wird.
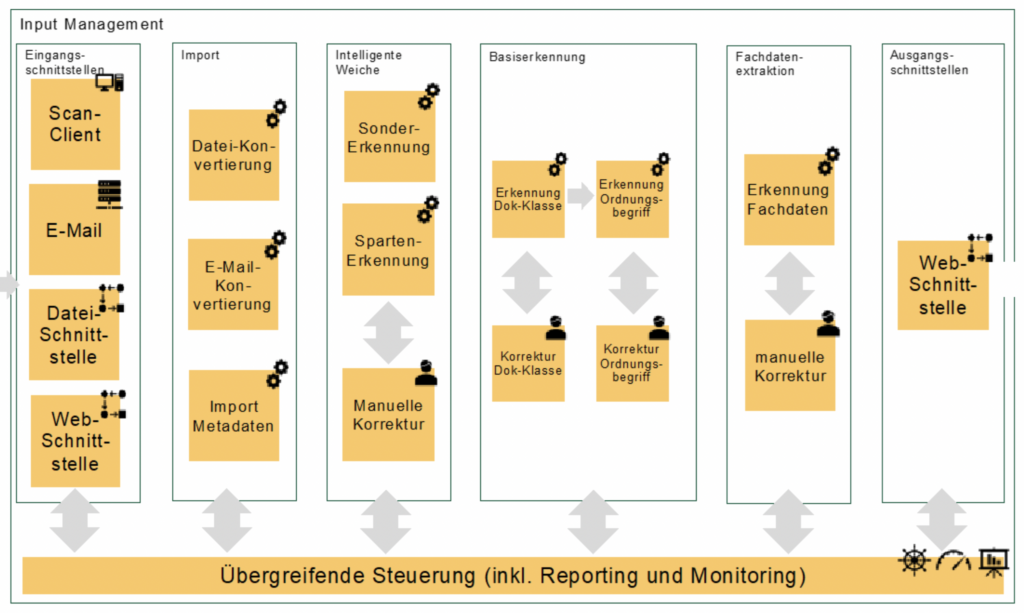
Das Schaubild zeigt eine beispielhafte Zielarchitektur zur Erweiterung einer bestehenden Input Management Lösung mit modernen KI-Services.
Wie im Artikel „Wie verändert Künstliche Intelligenz (KI) das heutige Input Management und somit auch das Anliegenmanagement?“ beschrieben, haben klassische Input Management Lösungen ihre Stärken in der Vorverarbeitung (engl. Pre-Processing), der Dokumentenklassifikation und der Identifikation des Vertragszusammenhangs. Die in der Zielarchitektur dargestellten Bereiche Eingangs- und Ausgangsschnittstellen, Im- und Export sowie die Basiserkennung können somit von klassischen Input Management Lösungen abgedeckt werden.
KI-Services können theoretisch bei allen Prozessschritten eingesetzt werden, wo eine maschinelle Verarbeitung notwendig ist. Im Schaubild sind diese Prozessschritte mit zwei Zahnrädern symbolisiert. Zum Beispiel könnten KI-Services im Bereich der OCR, des intelligenten Routings oder der Erkennung von Fachdaten eingesetzt werden.
Zur Integration von KI-Services in eine bestehende Input Management Lösung sowie zur Umsetzung des im Schaubild abgebildeten Schichtenmodells ist eine „starke“ übergreifende Steuerungsschicht entscheidend. Sollte die bestehende Input Management Lösung nicht über ausreichende Prozessorchestrierung verfügen, kann hier natürlich auch eine Lösung vom Markt eingesetzt werden. Oftmals sind jedoch entsprechende Lösungen des Unternehmens bereits in anderen Bereichen im Einsatz.
Anlassbezogene Fachdatenextraktion
Die anlassbezogene Fachdatenextraktion stellt einen neuen architektonischen Ansatz im Input Management dar.
Im klassischen Input Management wurden Fachdaten immer im Vorfeld zu der Folgebearbeitung, z.B. der Dunkelverarbeitung, ausgelesen. Durch diese vorzeitige Fachdatenextraktion kam es regelmäßig vor, dass mehr Fachdaten im Input Management erfasst wurden, als für die Dunkelverarbeitung notwendig waren. Nehmen wir als Beispiel an: Es wurde eine pauschale Regulierung zur Regulierung von Schadenfällen vereinbart. Das bedeutet, dass Schäden bis z.B. 100 Euro ohne Prüfung reguliert werden. In diesem Beispiel wäre es folglich ausreichend, dass das Input Management neben der Schadennummer nur den Rechnungsbetrag initial ausliest. Die Positionsdaten zum Schaden jedoch nur ab einem Rechnungsbetrag von über 100 Euro, bzw. wenn die Dunkelverarbeitung aussteigt und weitere Fachdaten in der anlassbezogenen Fachdatenextraktion anfordert.
Die anlassbezogene Fachdatenextraktion reduziert die manuellen Aufwände bei der Nachbearbeitung der Fachdatenextraktion im Input Management und beschleunigt die Verarbeitung eines Kundenanliegens.
Zur Konzeption gehören jedoch auch wichtige Planungselemente für eine reibungslose Einführung. Hierzu gehören Kostenschätzungen, Ressourcenplanung für die Einführung sowie Handlungsempfehlungen zur Systemauswahl und -implementierung.
Im folgenden dritten Artikel zum Thema KI im Input Management geben wir konkrete Hinweise, welche Besonderheiten bei der Produktauswahl beachtet werden sollten und wie sich der Markt für KI-Lösungen mit Fokus auf das Input Management entwickelt.
Hier finden Sie die Begriffsdefinitionen der Fachbegriffe aus der Artikelserie.
BegriffDefinition
Active Learning
Active Learning ist eine Variante des maschinellen Lernens bei der sich Algorithmen selbstständig optimieren und Vorschläge liefern können, welche weiteren Datenannotationen den größten Mehrwehrt für die Verbesserung des Modells in der bestimmten Problemstellung bringen.
Artificial Intelligence (AI)
engl. für Künstliche Intelligenz (KI)
Blatt
Physikalisches Blatt, in beliebigem Format das aus zwei Seiten besteht, die nicht zwingend bedruckt sind.
Computer Vision
Computer Vision ist ein Feld innerhalb der KI, die aussagefähige Informationen aus digitalen Bildern, Videos und anderen Visuellen Eingaben gewinnen kann.
Deep Learning
Deep Learning ist ein Teilbereich des maschinellen Lernens und der Bereich, der das Thema KI in den kommenden Jahren am stärksten beflügeln wird. Bei Deep Learning handelt es sich um eine Lernmethode bei dieser mittels neuronaler Netze die Maschine in die Lage versetzt wird, Strukturen zu erkennen, diese Erkennung zu überprüfen und sich in mehreren vorwärts wie rückwärts gerichteten Durchläufen selbständig zu verbessern.
Dokument
Hierbei handelt es sich im Inputmangement um Schriftstücke, die per Post, Fax oder E-Mail eintreffen mit Aufforderungen, bestimmte Handlungen (= Geschäftsvorfälle) vorzunehmen. Auch die Objekte, die per App eingereicht oder über Portale hochgeladen werden, beinhalten Dokumente. Dokumente sind grundsätzlich unstrukturierte Aufträge. Bei ihnen ist der beauftragte Geschäftsvorfall aus dem Layout und dem Inhalt des Dokumentes herauszufinden. Eine Sendung kann aus mehreren Dokumenten bestehen. Ein Dokument kann mehrere Geschäftsvorfälle beinhalten.
Ein Dokument besteht aus mindestens einem Blatt.
Dokumentenart
Genau eine fachliche Klassifizierung eines Dokuments. Eine Dokumentenart kann mehrere Dokumentenklassen beinhalten. Beispiel: Dokumentenart Rechnung.
Dokumentenklasse
Fachliche Klassifizierung eines Dokuments. Mehrere Dokumentenklassen können auf eine Dokumentenart verweisen.
Dokumentenklassifikation
Zuordnung einer Dokumentenklasse und einer Dokart zu einem Dokument
Dunkelverarbeitung
Von Dunkelverarbeitung ist die Rede, wenn Anliegen vollständig automatisiert und ohne menschliches Eingreifen im Hintergrund ablaufen.
End-to-End (E2E)
Von End-to-end-Bearbeitung bzw. End-to-end-Prozess ist die Rede, wenn eine zeitlich-logische Abfolge von Tätigkeiten/Prozessen ausgeführt wird, um eine konkretes Kundenanliegens zu erfüllen. End-to-end soll verdeutlichen, dass sich die Bearbeitung, der Prozess vom Bedarf des Kunden bis zur Leistungserbringung erstreckt und in der Regel abteilungsübergreifend ist.
Extraktion
Unter Extraktion wird im Input Management die Erkennung von Fachdaten (z.B. Versichertenname und –nummer) von einem Dokument verstanden.
Fachdatenextraktion
Die Fachdatenextraktion geht über die reine Indizierung zum Routing hinaus. Bei der Fachdatenextraktion werden weitere Dokumentinhalte extrahiert, um so eine manuelle Erfassung in der Sachbearbeitung zu vermeiden.
Generative KI
Generative KI ist in der Lage, mithilfe generativer Modelle Texte, Bilder oder andere Daten zu generieren.
Hellverarbeitung
Von Hellverarbeitung ist die Rede, wenn Geschäftsprozesse nicht- oder nur teilautomatisiert ablaufen, d.h. nur mit menschlichem Eingreifen fallabschließend bearbeitet werden können.
Indizierung
Von Indizierung wird im Input Management gesprochen, wenn die durch die Klassifizierung erkannte Dokumentenklasse und der durch Extraktion ausgelesene Ordnungsbegriff (z.B. Versicherungsnummer, Schadennummer) für die automatische Verteilung der Dokumente an die fachlich zuständigen Mitarbeiter verwendet wird.
Input Management (IPM)
Unter Input Management versteht man die Herangehensweise zur digitalen Erfassung von geschäftsrelevanten Daten aus verschiedenen Kommunikationskanälen und Kommunikationsformaten (z.B. Papierdokumente) und die Übergabe der Informationen an nachfolgende Geschäftsanwendungen.
Intelligent Document Processing (IDP)
Intelligent Document Processing (IDP) beschreibt die nächste Generation der Input Management Lösungen, welche unstrukturierte Daten mittels KI-Technologien in verwertbare Daten umwandelt, welche dann die Basis für die Automatisierungsinitiativen und die Optimierung des Anliegenmanagement in Unternehmen darstellen.
Klassifikation
Maschinelle Zuordnung einer Dokumtenklasse zu einem Dokument im Input Management. Anhand der Dokumentklassifikation kann in einem Folgeschritt die Zuordnung der eingehenden Kommunikation zu einem oder mehreren Anliegen erfolgen.
Künstliche Intelligenz (KI)
Im Allgemeinen bezeichnet Künstliche Intelligenz den Versuch, bestimmte Entscheidungsstrukturen des Menschen nachzubilden, indem z. B. ein Computer so gebaut und programmiert wird, dass er relativ eigenständig Probleme bearbeiten kann. Schaut man bei Künstliche Intelligenz einmal eine Ebene tiefer so ist häufig von „Deep Learning”, maschinellem Lernen, neuronalen Netzen und „Natural Language Processing” die Rede.
Large Language Models (LLMs)
LLMs sind fortschrittliche KI-Modelle, die sich durch die Fähigkeit Sprache zu verstehen, zu generieren und darauf zu reagieren auszeichnet. LLMs können Textverarbeitungsaufgaben durchführen, Fragen beantworten, Konversationen führen, Texte generieren und vieles mehr. Große Sprachmodelle erlangen diese Fähigkeiten durch die Verwendung großer Datenmengen. Große Sprachmodelle sind im weiteren Sinne künstliche neuronale Netze und werden entweder durch selbstüberwachtes Lernen oder halbüberwachte Lernmethoden trainiert.
Monitoring
Monitoring steht synonym für die technische Überwachung der Verarbeitung von Sendungen im Input Management. Hier tritt insbesondere die Einhaltung der vorgesehenen SLAs in den Vordergrund. Damit ist die Kontrolle der Durchlaufzeiten des Posteingangs durch die Erfassung gemeint. Um den Grundstein einer schnellen Bearbeitung des Posteingangs beim Sachbearbeiter zu legen, muss in vielen Unternehmen eine tag-gleiche Verarbeitung des Posteingangs sichergestellt werden. Um diese überwachen und bei Störfällen schnell an der richtigen Stelle eingreifen zu können, ist das technische Monitoring der Input Management-Lösungen von Bedeutung.
OCR
Abk. für Optical Character Recognition engl. für Optische Zeichenerkennung
Optische Zeichenerkennung
Optische Zeichenerkennung ist eine Methode zur Umwandlung von Texten, die nicht in Form von maschinenlesbaren Zeichen, sondern im Bildformat vorliegen, in eine kodierte, vom Rechner verarbeitbare Zeichenfolge (kodierte Information).
Pre-Processing
engl. für Vorverarbeitung
Reporting
Vorgangsbezogene Auswertungen bzw. Statistiken lassen sich mit Hilfe von Reporting-Komponenten im Input Management erstellen. So können im Reporting z. B. die durchschnittliche Prozesslaufzeit oder die maschinelle Erkennungsrate dargestellt werden.
Sendung
Inhalt eines Kuverts oder einer Email, der aus mehreren Dokumenten eines oder auch unterschiedlicher Kunden bestehen kann.
Supervised Learning
Supervised Learning ist eine Variante des maschinellen Lernens. Dabei werden für das Trainieren des Systems gegebene Paare von Ein- und Ausgabedaten herangezogen. Das Lernen erfolgt durch die Bereitstellung des korrekten Ausgabewerts, der zu einer Eingabe gehört.
Validierung
Zur Überprüfung von erkannten Dokumentinhalten und Validierung mit Daten aus Fachsystemen werden Validierungswerkzeuge oder -Regeln eingesetzt. So kann z.B. geprüft werden, ob die erkannte Schadennummer mit einem bereits gemeldeten Schaden übereinstimmt.
Vorgang
Der Begriff Vorgang wird häufig in Input Management-Lösungen synonym zum Begriff Sendung verwendet.
Vorverarbeitung
In der Vorverarbeitung werden papierbasierte Eingangsdokumente, E-Mails, Faxe, Fotos von mobilen Endgeräten, elektronische Dateien oder Inhalte aus dem Internet zur weiteren Bearbeitung importiert, konvertiert, qualitativ optimiert und entsprechend des Eingangskanals vorbereitet. Dazu zählt auch der Schritt der OCR-Erkennung.
Guido Schmitz ist Mitbegründer und Vorstandsmitglied der Pentadoc AG.
Als Berater betreut Guido Schmitz Unternehmen in Prozessen der Strategieentwicklung im Bereich Informationslogistik, führt und moderiert Workshops zum Anforderungsdesign. Guido Schmitz ist ein gefragter Keynotespeaker auf Strategietagungen und Kongressen.
Guido Schmitz ist Mitbegründer und Vorstandsmitglied der Pentadoc AG.
Als Berater betreut Guido Schmitz Unternehmen in Prozessen der Strategieentwicklung im Bereich Informationslogistik, führt und moderiert Workshops zum Anforderungsdesign. Guido Schmitz ist ein gefragter Keynotespeaker auf Strategietagungen und Kongressen.