Experteninterview: KI Hype im Input Management
Wir haben Sascha Ehrenforth in einem Interview gebeten, seine Sicht auf die aktuellen Entwicklungen rund um den Begriff des Intelligent Document Processing (IDP) mit uns zu teilen.
Sascha Ehrenforth beschäftigt sich seit über 10 Jahren mit angewandter Künstlicher Intelligenz. Als Leiter Input-/Outputservice bei der NÜRNBERGER Versicherung ist er verantwortlich für die Digitalisierung von dokumentengetriebenen Geschäftsprozessen und deren Automation/Dunkelverarbeitung, was in der Weitergabe der Dokumente als eindeutig klassifizierbarer Geschäftsvorfall, inklusive aller benötigter Nutzdaten mündet.
Pentadoc: Wie bist du zum Thema Dokumenten-Management unter Einsatz von Künstlicher Intelligenz gekommen?
 Sascha Ehrenforth: Die Idee Dokumente zu klassifizieren und Daten zu extrahieren ist ja nicht neu. Die Interpretation von OCR-generierten Texten mit KI-Bestandteilen und Machine Learning-Ansätzen gibt es schon seit 20 Jahren. Ich bin als Prozessmanager und Verfechter von Digitalisierung zu diesem Werkzeug gekommen und habe mich dann tiefer mit der Materie beschäftigt. Nun begleitet mich das Thema schon über ein Jahrzehnt und auch in meiner Führungsrolle spielt KI nun eine große Rolle.
Sascha Ehrenforth: Die Idee Dokumente zu klassifizieren und Daten zu extrahieren ist ja nicht neu. Die Interpretation von OCR-generierten Texten mit KI-Bestandteilen und Machine Learning-Ansätzen gibt es schon seit 20 Jahren. Ich bin als Prozessmanager und Verfechter von Digitalisierung zu diesem Werkzeug gekommen und habe mich dann tiefer mit der Materie beschäftigt. Nun begleitet mich das Thema schon über ein Jahrzehnt und auch in meiner Führungsrolle spielt KI nun eine große Rolle.
Pentadoc: Kann KI denn das, was es verspricht, was ist deine Einschätzung? Wie du richtigerweise gesagt hast, ist KI im Dokumenten- beziehungsweise Input-Management eher ein „alter Hut“. Was ist also jetzt neu daran?
Sascha Ehrenforth: KI ist nun an dem Punkt, an dem es viele der hohen Managementerwartungen der Vergangenheit erfüllen kann. Immer mehr Use-Cases werden realisierbar und das stärkt die Attraktivität solcher Initiativen.
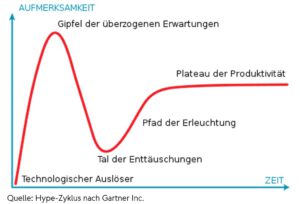
Quelle: Hype-Zyklus nach Gartner Inc.
Mit der heutigen Rechenleistung ist es möglich beziehungsweise in dem Kontext finanziell tragbar, dass nun auch semantische Zusammenhänge und Bildelemente erkannt und verarbeitet werden. So wie beispielsweise Siri, Alexa und auch ChatGPT aus Sprache Text machen und diese interpretieren, so machen wir im Input-Management aus Bildern Text und verarbeiten diese weiter.
Dabei werden sowohl die Module, die aus Bildern Text machen (OCR genannt) immer besser, beispielsweise zur Erkennung von Handschrift oder Bilder mit schlechter Qualität, als auch die NLP (Natural Language Processing) Module, welche Kontext verstehen können. Viele Anbieter von Intelligent Document Processing (IDP) Plattformen haben diese Softwarekomponenten integriert und können nach Systemintegration von Mitarbeitenden ohne tiefe Programmierkenntnisse (Low-Code) genutzt werden.
Pentadoc: Brauchen Firmen zukünftig also keine Entwickler*innen mehr, um KI zu nutzen?
Sascha: Das habe ich nicht gesagt, wobei der eine oder andere Anbieter durchaus diese These vertritt. Was ich sagen möchte, ist, dass die Einstiegshürde, Künstliche Intelligenz zu nutzen, immer geringer wird. Die Komplexität sinkt und das ist erstmal gut. Das wiederum ist – in meinen Augen – Fluch und Segen zugleich. Einem Konzern, der bereits Spezialwissen im Umgang mit diesen Ansätzen aufgebaut hat, schwindet der Wettbewerbsvorteil. Die Konzerne, welche KI im Input-management nutzen, rücken also „näher zusammen“. Der Unterschied zwischen den Anwender-Konzernen, welche KI nutzen gegenüber jenen, welche dort noch gar nicht aktiv sind, wird dagegen weiter zunehmen.
Pentadoc: Du sprichst es an, Siri und Alexa gibt es schon und auch andere große Tech-Unternehmen drängen auf den Markt. Werden mit KI in der Zukunft also alle Probleme gelöst?
Sascha: Naja, nicht ganz, ein entscheidendes Detail fehlt dann doch noch. Das fehlende Puzzleteil ist das branchen- und unternehmensspezifische Wissen. Wenn ich beispielsweise als Versicherung eine individuelle Information aus einem Eingangsdokument extrahieren möchte, so muss ich das der Künstlichen Intelligenz beibringen. Ich mache ein Beispiel: Es gilt die Sparte und Schadenart „KFZ-Teilkasko – Wildschaden“ aus einer Schadenmeldung zu ermitteln. Dies wird der Kunde aber so nicht auf sein Dokument schreiben.
Wir müssen also die Beschreibung des Unfallhergangs „Mir ist bei der Fahrt durch ein Waldstück ein Reh vor das Auto gelaufen“, in diese Terminologie übersetzen. Die zu erkennenden Sparten und Schadenarten unterscheiden sich von Versicherer zu Versicherer aufgrund der unterschiedlich organisierten Verarbeitung der einzelnen Vorfälle, sodass die Anbieter nur schwer eine Universallösung vordefinieren können.
Pentadoc: Was können wir also zukünftig von Künstlicher Intelligenz in der Dokumentenverarbeitung erwarten, beziehungsweise was wird deiner Meinung nach der Nutzen sein?
Sascha: Die Strukturierung von Eingangsdaten ist die Basis und somit der Enabler für die Dunkelverarbeitung (sprich: automatische Verarbeitung) in den Folgesystemen. Mit einer konsequenten Verlagerung der Datenstrukturierung nach Vorne in das Inputmanagement können nicht nur Kosten durch Automation eingespart, Mitarbeiter entlastet, sondern auch Kundenerlebnisse durch die schnellere Bearbeitung geschaffen werden.
Den Kunden glücklich machen, so einfach ist es!
Pentadoc: Ein großartiges Schlusswort, lieber Sascha, wir bedanken uns für das Interview!
Weiterführende Links
|
IT-Projekte & Management
Das Dopix Fiasko | |
Künstliche Intelligenz
KI Hype im Input Management | |
|
Prozessmanagement & -optimierung
Prozess Management für Versicherungen | |
Versicherungsberatung
Unternehmensberatung Versicherung | |
|
Digitale Transformation & IT-Strategie
Digitale Transformation Versicherung | |
Software & Dokumentenmanagement
Software für Versicherungen | |










