
Die Wertschöpfungskette des Input Management – eine Detailbetrachtung
Von Papier zu Daten – Dokumentinhalte digital erfassen, verstehen und verteilen.
Das Input Management als Prozess der Inhaltserfassung von analogen und digitalen Daten stellt eine der bedeutendsten Disziplinen in der Informationslogistik dar. Denn die Effizienz der schriftbasierten Geschäftsprozessbearbeitung ist untrennbar mit der Qualität der erfassten Inhalte verbunden. Hierbei lohnt sich ein Blick auf einzelne Prozessschritte, um Potentiale fokussiert erkennen zu können.
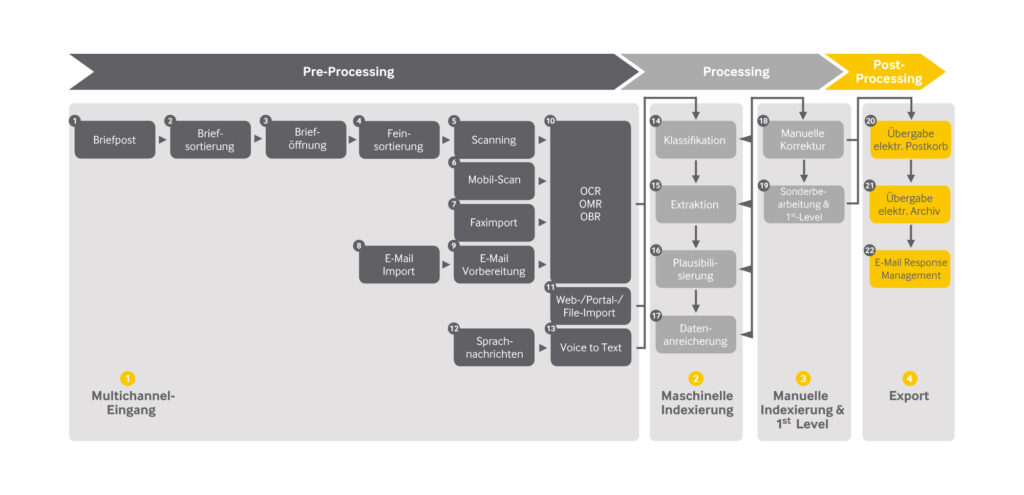
Die Prozessschritte können wie folgt beschrieben werden:
- Briefpost
Die eingehende Briefpost wird von den entsprechenden Postlogistikern entgegengenommen. - Briefsortierung
Die entgegen genommen Briefe werden sortiert nach den Gesichtspunkten „öffnen“ oder „nicht öffnen“. - Brieföffnung
Die mit „öffnen“ klassifizierten Briefe werden geöffnet. Hierfür werden in der Regel Brieföffnungstechnologien verwendet. - Feinsortierung
Im Bereich Feinsortierung werden alle Sortier- und Vorbereitungstätigkeiten für das spätere Digitalisieren der Briefpost subsummiert. Dazu gehören das Sortieren nach z.B. Sonderformaten, Mandanten, Prozesstypen und Prozessuntertypen aber auch die Scannaufbereitung: Entklammern, Aufbereitung von einzelnen Seiten, Glätten, Einfügen von Trennblättern bzw. Aufbringen von Barcodes zur Vorgangs-/Dokumententrennung. - Scanning
Beim Scanning werden die analogen papierbasierten Dokumente mit Hilfe von MFPs, Tisch- oder Produktionsscannern in digitale Dateiformate gewandelt. - Mobil-Scanning
Mit mobilen Apps können papierbasierte Dokumente vom Kunden oder Partner direkt in das Input Management eingescannt werden. - Faximport
Beim Faximport werden die Faxe direkt vom Faxserver übernommen. Zusätzlich findet noch eine Bildverbesserung z.B. im Bereich Stauchung und Skalierung statt. - E-Mail-Import
Über den E-Mail-Import können elektronische Dateien aus E-Mail-Systemen (Exchange, Lotus Notes) in das Input Management importiert werden. - E-Mail Vorbereitung
E-Mails werden so konvertiert, dass in den nachfolgenden Prozessschritten der E-Mail-Body und die E-Mail-Anhänge separat analysiert werden können. Häufig ist dazu auch eine Konvertierung der E-Mail-Anhänge in ein maschinenlesbares Format notwendig. - OCR, OMR, OBR
Optical Character Recognition (OCR) ist eine Methode zur Umwandlung von Texten, die nicht in Form von maschinenlesbaren Zeichen, sondern im Bildformat vorliegen, in eine kodierte, vom Rechner verarbeitbare Zeichenfolge (kodierte Information). Zusätzlich können mittels der Optical Mark Recognition (OMR) Markierungen (z.B. Ankreuzfelder) und mit der Optical Barcode Recognition (OBR) Barcodes und Datamatrix-Codes erkannt werden. - Web-/Portal-/File-Import
Über den Web-/Portal-Import können elektronische Dateien aus Internetseiten bzw. Internetportalen in das Input Management importiert werden. Über den File-Import können elektronische Dateien aus dem Dateisystem in das Input Management importiert werden. - Sprachnachrichten
Sprachnachrichten werden beispielsweise von einer Telefonanlage in das Input Management importiert. - Voice to Text
Mit Voice to Text werden gesprochenen Worte in verarbeitbare Zeichenfolgen konvertiert. - Klassifikation
Maschinelle Zuordnung eines Dokumenttyps bzw. einer Dokumentklasse zu einem gescannten Dokument. - Extraktion
Maschinelles Auslesen von Dokumentfeldern von gescannten Dokumenten. - Plausibilisierung
Fehlertolerante Überprüfung der via Extraktion erfassten Dokumentfeldern anhand von Referenzdatenbanken. - Datenanreicherung
Anreicherung der extrahierten Dokumentfeldern anhand von Referenzdatenbanken. - Manuelle Korrektur
Im Klassifikation und Extraktion nicht erkannte Dokumenttypen oder Dokumentfelder werden manuell nachbearbeitet und die Daten vervollständigt. - Sonderbearbeitung & 1st Level
Fehlende zur Weiterverarbeitung notwendige Daten werden durch Rückfragen manuell beschafft. Von 1st Level-Bearbeitung, Breitenbearbeitung oder Einfachsachbearbeitung spricht man, wenn einfache Geschäftsvorfälle fallabschließend bearbeitet werden. Z.B. fällt die Bearbeitung einer Rücksendung, inkl. der notwendigen Adressermittlung in diesen Bereich. - Übergabe elektronische Postkorb
Metadaten und das Dokument werden an den elektronischen Postkorb zur weiteren Vorgangsbearbeitung gegeben. - Übergabe elektronisches Archiv
Metadaten und das Dokument werden an das elektronische Archiv zur revisionssicheren Archivierung übergeben. - E-Mail Response Management
Metadaten, das Dokument und die E-Mail im Originalformat werden an ein System zur automatisierten E-Mail-Beantwortung übergeben.
Weiterführende Links
|
IT-Projekte & Management
Das Dopix Fiasko | |
Künstliche Intelligenz
KI Hype im Input Management | |
|
Prozessmanagement & -optimierung
Prozess Management für Versicherungen | |
Versicherungsberatung
Unternehmensberatung Versicherung | |
|
Digitale Transformation & IT-Strategie
Digitale Transformation Versicherung | |
Software & Dokumentenmanagement
Software für Versicherungen | |










